投稿到 CNTUG 2024/10 分享之後,有一些更新內容
Kubernetes 支援用 Scheduler Profile 的方式設定排程策略,如果你的排程策略可以用預設的 Plugins,推薦使用這個就好。
用官方提供的案例:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: no-scoring-scheduler
plugins:
preScore:
disabled:
- name: '*'
score:
disabled:
- name: '*'
這個 no-scoring-scheduler 會跟 default-scheduler 同時存在,只要你的 pod.spec.schedulerName 設定為 no-scoring-scheduler,這個 Pod 就會由 no-scoring-scheduler 進行排程。
如果預設的 Plugins 沒辦法滿足你的需求,可以自己開發一個 Custom Plugins,然後佈署到 Kubernetes 當中。
kube-scheduler-simulator 提供一個簡單的 Custom Plugins,其中可以窺見開發以及佈署 Plugins 的方式,只要實作對應的 Interface,然後在 Scheduler 載入,就可以運行了。有興趣的可以佈署看看,這邊提供 kss 的範本。
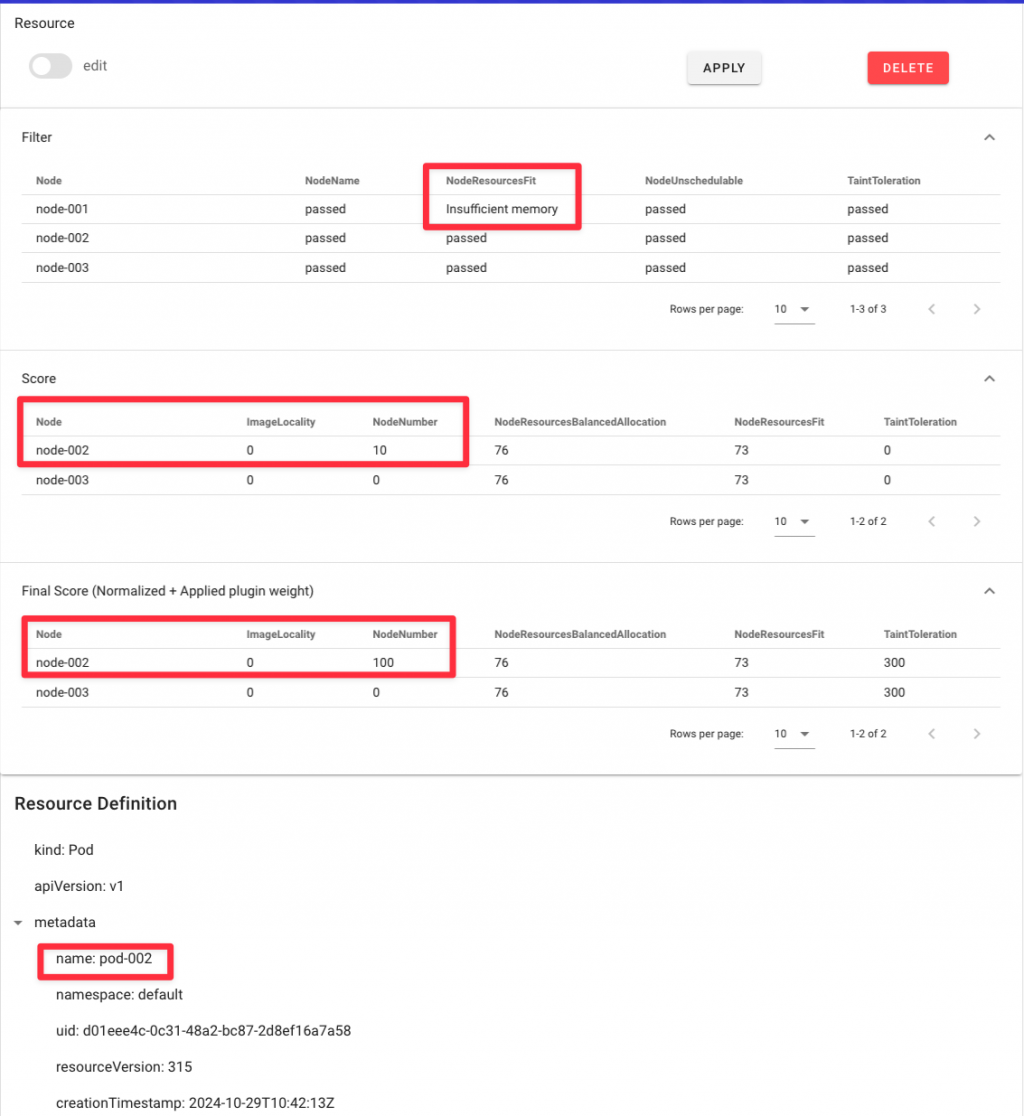
這個 Plugin 會根據最後一位數字找到 Node,比如說
Pod-001 會優先排程到 Node-001
Pod-002 會優先排程到 Node-002
我佈署了一個 Pod-002,在評分階段,Node-002 得到最高分,並在之後加權 x10
遺留功能,有效能以及錯誤管理的問題,盡量用前兩者方法。
關於 Kubernetes Scheduler,觀察到三個有趣的趨勢
當節點資源緊張時,kubelet 負責發動 Node Pressure Eviction,驅逐資源使用過多的 Pod。
但是,kubelet 在發動 Node Pressure Eviction 的時候,不會去溝通 Control Plane,沒辦法得知 Cluster 狀態。
因為 kubelet 沒辦法得知 cluster status,這個問題導致 kubelet 很難做出積極的排程策略,比如說:
Node A 上面的 kubelet 觀察到 memory 85%,為了保留 Memory 給重要的 Pod 使用,所以想要驅逐 Pod。
但是 kubelet 並不知道 Node A 之外的節點狀態,比如說 Node B 是不是也同樣在忙?還是 Node C 是現在最閒的,所以可以把被驅逐的 Pod 丟到 Node C 上面。
kubelet 並不知道 Cluster 狀態,所以很難做出積極且有效的驅逐策略。
Descheduler 就是在解決的這個問題,讓我們可以利用 Cluster 狀態做出更積極且有效的排程策略。
Descheduler 主要提供兩個功能:
如上所敘,根據 Cluster 狀態做出主動的驅逐,避免 OOM 發生。
排程策略在佈署之後就會失效,為了主動遵循排程策略,所以 Descheduler 可以在違反排程策略的情況下,主動重啟 Pod。
Machine Learning 使用的 Batch Job 跟平時 Application 的性質很不一樣,有許多 CNCF Project 在處理這個問題,目前我看到最有潛力,架構最整潔的是 Kueue。
Pro:
Kueue 可以定義多層次的 Queue,並根據 Job 性質把 Job 塞到各個 Queue,例如推論的進到推論的 Queue,訓練的進到訓練的 Queue,推論資源不夠還可以去借用訓練的資源。
每個 Queue 都可以設定資源,比如說推論跟訓練性質不同,所以優先選擇各自的 GPU
如果某個 Queue 太忙了,還可以跑去借別人的資源,這邊的資源不只是自己定義的,甚至可以去借用雲端的。
Job 進 Queue 之後,Priority 還是可以重排:比如說前面排了三個訓練內部系統使用的小模型,後面突然進來一個用戶使用的訓練模型,這是前面三個訓練小模型的任務,會因為後面進來的訓練優先級較高,所以讓給後面進來的訓練任務。
用 WebAssembly 的靈活特性作為 Proxy,讓大家可以靈活擴充 kube-scheduling。


 iThome鐵人賽
iThome鐵人賽